

Data Quality trong quant trading: Clean data = quyết định đúng
Clean data = quyết định đúng
Data Quality trong quant trading: Clean data = quyết định đúng
Trong quant trading, nhiều người thường nghĩ lợi thế nằm ở mô hình phức tạp, AI, machine learning hay thuật toán tốc độ cao. Nhưng thực tế, trước cả mô hình, thứ quyết định hệ thống có đáng tin hay không lại là chất lượng dữ liệu. Một mô hình rất thông minh nhưng học từ dữ liệu sai có thể tạo ra kết quả nguy hiểm hơn cả việc không dùng mô hình nào. Trong giới quantitative trading có một câu khá nổi tiếng: “Garbage in, garbage out.” Dữ liệu đầu vào sai thì đầu ra gần như chắc chắn sai.
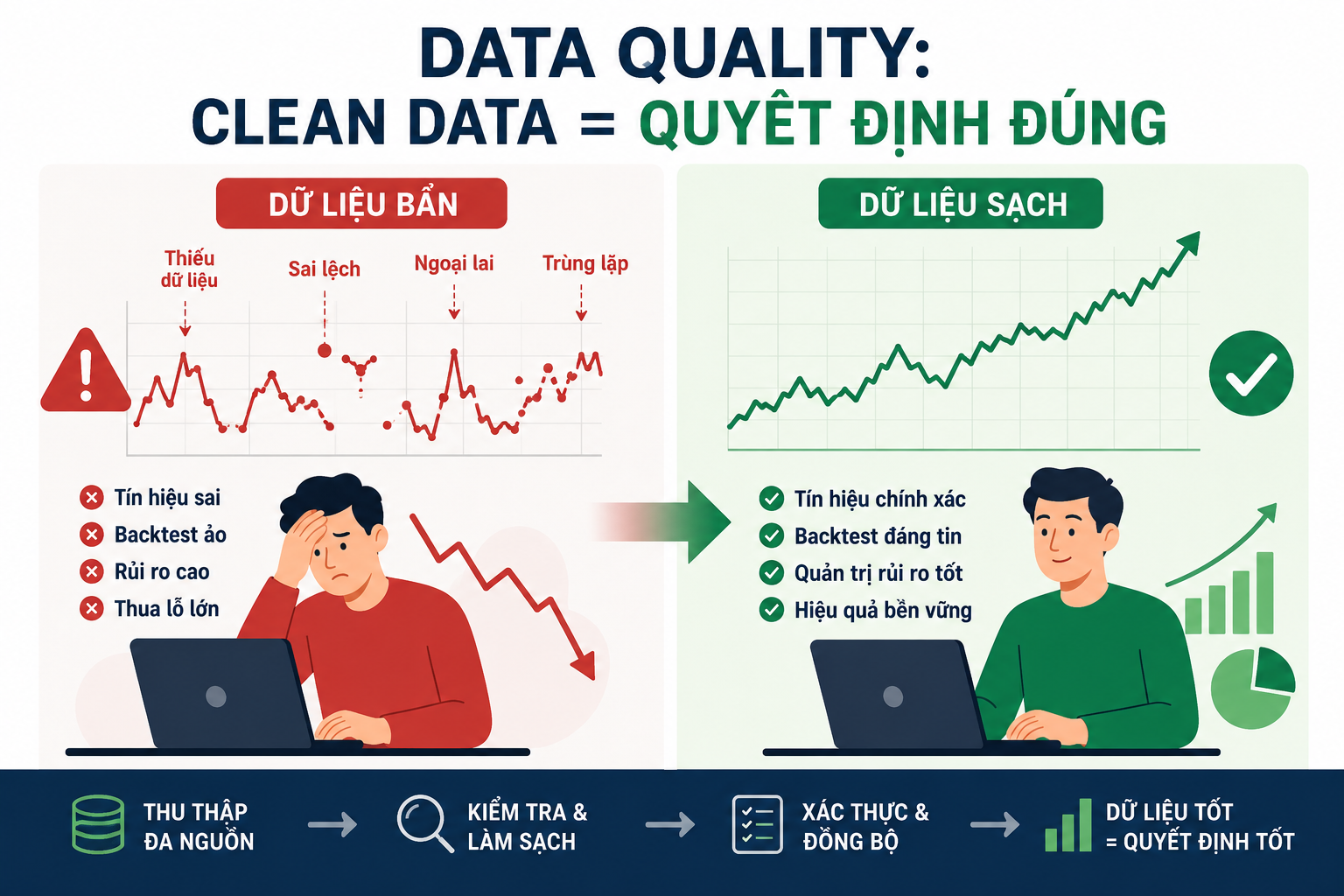
Điều này nghe rất kỹ thuật, nhưng thực ra cực kỳ thực tế. Một trader discretionary có thể nhìn chart và tự nhận ra dữ liệu bất thường bằng mắt. Nhưng hệ thống quant thì không “hiểu” dữ liệu như con người. Nó chỉ xử lý những gì được đưa vào. Nếu dữ liệu bị lỗi, bị thiếu, bị lệch thời gian hoặc bị sai logic, mô hình có thể tạo ra tín hiệu rất đẹp trong backtest nhưng hoàn toàn vô dụng ngoài thị trường thật. Đây là lý do trong nhiều quỹ quant lớn, phần lớn thời gian không nằm ở việc “viết alpha”, mà nằm ở việc làm sạch, kiểm tra và xác thực dữ liệu.
1. Vì sao chất lượng dữ liệu quan trọng hơn nhiều người nghĩ
Một hệ thống quant thực chất là quá trình biến dữ liệu thành quyết định. Giá cổ phiếu, volume, order flow, báo cáo tài chính, lãi suất, tỷ giá, CPI, sentiment, dữ liệu options hay thậm chí dữ liệu vệ tinh đều có thể trở thành input cho mô hình. Nhưng nếu dữ liệu đầu vào sai, mô hình sẽ học sai quy luật thị trường.
Ví dụ rất đơn giản: một chiến lược momentum có thể dùng điều kiện “mua khi giá vượt MA20 với volume tăng mạnh”. Nếu dữ liệu volume bị lỗi, ví dụ một ngày nào đó volume bị nhân lên gấp 10 lần do lỗi feed, hệ thống có thể hiểu nhầm rằng đang có dòng tiền cực mạnh và phát tín hiệu mua hàng loạt. Backtest có thể cho kết quả rất đẹp vì hệ thống “thấy” những phiên breakout giả không tồn tại ngoài đời thật.
Một ví dụ khác là dữ liệu giá chưa adjusted. Khi cổ phiếu chia tách, trả cổ tức hoặc phát hành thêm, giá lịch sử cần được điều chỉnh lại để phản ánh đúng biến động thực. Nếu không adjusted, mô hình có thể hiểu nhầm rằng cổ phiếu vừa “gap down” rất mạnh, trong khi thực tế đó chỉ là điều chỉnh kỹ thuật sau chia tách cổ phiếu. Rất nhiều hệ thống backtest của người mới nhìn có lợi nhuận cực cao chỉ vì dữ liệu chưa được xử lý đúng.
Trong The Quants, Scott Patterson cũng nhắc rất nhiều đến việc các quỹ định lượng không chỉ cạnh tranh bằng thuật toán, mà còn cạnh tranh bằng dữ liệu. Người có dữ liệu sạch hơn, nhanh hơn và được xử lý tốt hơn thường có lợi thế lớn hơn. Renaissance Technologies, Two Sigma hay Citadel đều đầu tư cực mạnh vào infrastructure dữ liệu, vì họ hiểu rằng edge không chỉ nằm ở mô hình, mà nằm ở việc dữ liệu có phản ánh đúng thực tế thị trường hay không.
Điểm nguy hiểm nhất của dữ liệu bẩn là nó thường tạo cảm giác rất thuyết phục. Một chiến lược backtest lợi nhuận đẹp, drawdown thấp, Sharpe ratio cao nhìn cực kỳ hấp dẫn. Nhưng nếu kết quả đó được tạo ra từ dữ liệu sai, thì toàn bộ hệ thống chỉ là một ảo giác toán học. Đây là lý do trong quant trading, nhiều người nói rằng “bad data is more dangerous than no data”. Không có dữ liệu thì bạn biết mình chưa đủ thông tin. Nhưng dữ liệu sai lại khiến bạn tự tin vào một thứ vốn không thật.
2. Những lỗi dữ liệu phổ biến trong quant trading
Nguồn lỗi dữ liệu trong quant trading nhiều hơn phần lớn người mới nghĩ. Một trong những lỗi phổ biến nhất là missing data, tức dữ liệu bị thiếu. Ví dụ một số phiên giao dịch không có giá close, volume hoặc bid-ask spread. Nếu mô hình không xử lý đúng, nó có thể tự fill bằng giá trước đó hoặc tạo ra chuỗi dữ liệu méo mó. Với chiến lược intraday hoặc high-frequency, chỉ vài mili giây dữ liệu thiếu cũng có thể làm kết quả khác hoàn toàn.
Lỗi phổ biến thứ hai là outlier, tức dữ liệu bất thường. Ví dụ cổ phiếu đang giao dịch quanh 50.000 đồng nhưng dữ liệu ghi nhầm một tick xuống 5.000 đồng rồi quay lại ngay sau đó. Với mắt người, đây rõ ràng là lỗi. Nhưng với hệ thống quant, đó có thể bị hiểu là một cú flash crash cực mạnh. Nếu chiến lược dựa trên volatility hoặc mean reversion, tín hiệu tạo ra sẽ hoàn toàn sai.
Lỗi thứ ba là survivorship bias, một trong những cái bẫy lớn nhất trong backtest. Rất nhiều người backtest chỉ với các cổ phiếu còn tồn tại hiện tại trên thị trường. Nhưng những công ty phá sản, bị hủy niêm yết hoặc biến mất lại không được tính vào dữ liệu. Điều này khiến kết quả backtest đẹp hơn thực tế rất nhiều, vì “người sống sót” thường là các doanh nghiệp khỏe hơn. Trong thực tế, nhà đầu tư không biết trước công ty nào sẽ tồn tại lâu dài.
Một lỗi khác rất nguy hiểm là look-ahead bias, tức mô hình vô tình sử dụng dữ liệu của tương lai để ra quyết định trong quá khứ. Ví dụ dùng báo cáo tài chính Q2 để giao dịch từ đầu quý, trong khi thực tế thời điểm đó thị trường chưa hề biết dữ liệu này. Backtest lúc đó sẽ đẹp giả tạo vì mô hình đang “biết trước tương lai”.
Ngoài ra còn có vấn đề timestamp mismatch, đặc biệt trong multi-asset trading. Ví dụ dữ liệu futures cập nhật theo mili giây nhưng dữ liệu cổ phiếu cập nhật chậm hơn vài giây. Nếu timestamp không đồng bộ, hệ thống có thể hiểu sai mối quan hệ dẫn dắt giữa các tài sản. Với HFT hoặc statistical arbitrage, đây là lỗi cực kỳ nghiêm trọng.
Một ví dụ thực tế nổi tiếng là sự kiện Knight Capital năm 2012. Chỉ vì lỗi triển khai hệ thống trading, công ty này mất khoảng 440 triệu USD chỉ trong khoảng 45 phút và gần như sụp đổ. Dù đây không hoàn toàn là lỗi dữ liệu, nó cho thấy trong trading tự động, chỉ một lỗi nhỏ trong hệ thống cũng có thể tạo hậu quả cực lớn.
Ở cấp độ nhỏ hơn, rất nhiều trader retail gặp vấn đề tương tự khi dùng dữ liệu miễn phí từ nhiều nguồn khác nhau. Một nguồn adjusted, nguồn khác không adjusted. Một nguồn dùng timezone khác. Một nguồn thiếu volume pre-market. Nếu không kiểm tra kỹ, mô hình sẽ cho kết quả inconsistent mà người dùng không hiểu nguyên nhân nằm ở đâu.
3. Clean data: cách các quant trader xử lý dữ liệu trước khi ra quyết định
Trong quant trading, làm sạch dữ liệu gần như là một bước bắt buộc trước khi xây mô hình. Một pipeline dữ liệu tốt thường có nhiều lớp kiểm tra thay vì chỉ tải dữ liệu về rồi chạy backtest ngay.
Bước đầu tiên thường là validation, tức kiểm tra dữ liệu có hợp lý không. Ví dụ volume có âm không, giá high có thấp hơn low không, dữ liệu có bị duplicate không, timestamp có liên tục không. Những lỗi logic cơ bản này nếu không phát hiện sớm sẽ làm hỏng toàn bộ mô hình.
Sau đó là xử lý missing values. Tùy chiến lược mà quant trader sẽ chọn cách fill dữ liệu khác nhau. Có trường hợp dùng forward fill, có trường hợp loại bỏ hoàn toàn phiên bị thiếu, hoặc dùng interpolation. Quan trọng là phải hiểu việc fill dữ liệu có làm méo tín hiệu không.
Tiếp theo là xử lý outliers. Một số quỹ dùng z-score hoặc volatility filters để phát hiện những điểm dữ liệu bất thường. Nếu một giá trị quá xa so với phân phối bình thường của chuỗi dữ liệu, hệ thống sẽ đánh dấu để kiểm tra lại thay vì đưa thẳng vào mô hình.
Một bước rất quan trọng khác là normalization và adjustment. Dữ liệu cần được adjusted cho stock split, cổ tức, thay đổi cấu trúc hợp đồng futures hoặc rollover. Nếu không, hệ thống sẽ “thấy” những biến động không có thật.
Các quant trader chuyên nghiệp cũng thường chia dữ liệu thành nhiều giai đoạn: training set, validation set và out-of-sample test. Mục đích là tránh overfitting, tức mô hình học quá kỹ dữ liệu quá khứ nhưng thất bại ngoài thị trường thật. Một chiến lược chỉ đáng tin khi nó hoạt động được trên dữ liệu mà mô hình chưa từng “nhìn thấy”.
Ngoài ra, nhiều quỹ lớn còn dùng multiple data vendors để đối chiếu dữ liệu. Nếu Bloomberg, Reuters và exchange feed cho kết quả khác nhau bất thường, hệ thống sẽ flag để kiểm tra. Vì trong quant trading, một dữ liệu sai có thể dẫn đến hàng triệu USD giao dịch sai.
Điều mình thấy thú vị là trong giới quant, rất nhiều alpha không đến từ “AI thần thánh”, mà đến từ việc xử lý dữ liệu tốt hơn người khác. Người có dữ liệu sạch hơn thường đã có lợi thế trước khi mô hình bắt đầu chạy.